AKQ gameのQuantal Response Equilibrium (QRE)
GTO Wizardが導入したQRE(質的応答均衡)をAKQ gameで解説。Logit QREの計算方法、Nash均衡との定量比較、exploitability評価、統計力学との対応まで。

文責:しぐま (Twitter: @sigm_4)
本稿でわかること
Quantal response equilibrium (QRE)とは何か
QREを具体的にどのように計算するか(logit QRE; LQRE)
Wizardで使われているQREはこれまでのNash均衡に基づくGTO戦略と定量的にどの程度異なるのか
(マニア向け) LQREではハンドの性質によってNash均衡への漸近的振る舞いが質的に異なる
(マニア向け) 統計力学との対応関係から混合戦略のエントロピーや自由エネルギーといった概念が適用できて、LQREが自由エネルギーに対する変分問題として定式化できる
導入:Quantal Response Equilibrium (QRE)
QREとは?
最近、GTO WizardがQuantal Response Equilibrium (QRE、質的応答均衡)と呼ばれる均衡戦略を導入したことが話題になっている(日本語記事、英語記事)。キーワードのQREやゴーストライン👻等についても、すでに日本語の解説noteが書かれている(狆crypto(siguo)氏、うっでぃ氏)。
これらのnoteやGTO Wizardの解説記事を参照した方はすでにQREがどのようなものか理解しているかもしれない。この記事では、改めてQREとは何かの説明から始め、その一つの計算方法(model)であるlogit QREについて解説し、最も基本的なtoy gameであるAKQ gameについての適用例を提示する。
QREとは、簡単に表現すると各プレイヤーが完全には合理的ではない場合の均衡である。従来のNash均衡に基づくGTO戦略では、完全に合理的なプレイヤー同士が相手プレイヤーの行動を正確に予測できるという強い仮定に基づいていた。QREでは、意思決定において完全合理的ではなく、お互いが確率的に"ミス"を犯すということを考慮する。
どのようなミスをどのような確率で起こすかについていくつかのmodelが存在し、その中で最も代表的なものがlogit QRE (LQRE)と呼ばれるものである。記事執筆時現在では、GTO Wizardの解説記事中にどのQREのmodelが使用されているかについての言及はない。そこで、本稿ではありうる可能性としてlogit QREを取り上げて解説を行い、均衡がどのように作られるのかを具体的に見ていくことでQREの実感を掴むことを目的とする。
代表例:Logit QRE (LQRE)
Logit QRE (LQRE)では、各アクションの選択確率が(相手の戦略を固定した場合に)そのアクションのEVに対して指数関数的に決まるとする。つまり、プレイヤー$i$がアクション$a_i$を取る確率は、
$$ \begin{align*} P_i(a_i) = \frac{e^{\lambda\cdot\mathrm{EV}(a_i,P_{-i})}}{\sum_{a_i'}e^{\lambda\cdot\mathrm{EV}(a_i',P_{-i})}} \quad\quad (1) \end{align*} $$
である。ここで、$P_{-i}$はプレイヤー$i$以外のプレイヤーの混合戦略の組とする。$\mathrm{EV}(a_i,P_{-i})$は、プレイヤー$i$がアクション$a_i$を採り、他のプレイヤーが混合戦略組$P_{-i}$を採った時にプレイヤー$i$が得られる期待利得を表す。また、$\lambda$は合理性パラメータと呼ばれる非負のパラメータである。
式(1)は、$\mathrm{EV}(a_i,P_{-i})$が大きくなれば$P_i(a_i)$が指数関数的に大きくなるということを表す。つまり、プレイヤーは(他プレイヤーの混合戦略組を固定した時に)EVの高いアクションを高頻度で採るということである。Nash均衡と異なる点は、各nodeで最大EVのアクションのみを採るというわけではないという点である。では、ベストアクション(=最高EVのアクション)以外のアクションはどの程度考慮されているのだろうか。それは合理性パラメータ$\lambda$によって決定される。$\lambda$が大きければ大きいほど、式(1)の指数を大きくするため、ベストアクションを採る確率は大きくなる。逆に言えば、大きな$\lambda$に対してはプレイヤーはベストアクション以外のアクションを採る確率が急激に低下する。
式(1)をベストアクション$a_i^{\mathrm{best}}$に関する項の$e^{\lambda\cdot\mathrm{EV}(a_i^{\mathrm{best}},P_{-i})}$で分母分子を割ってやると、$P_i(a_i) \sim e^{\lambda\cdot(\mathrm{EV}(a_i,P_{-i})-\mathrm{EV}(a_i^{\mathrm{best}},P_{-i}))}$ となることから、ベストアクションのEVに比べて$1/\lambda$程度低いEVを持つ戦略までが許容される(ある程度の確率を持つ)ことがわかる。すなわち、$\lambda\to\infty$の極限では、ベストアクションのみが許容され、プレイヤーは完全に合理的となってNash均衡(の一部)を与える。一方で、$\lambda\to 0$の極限では、すべての戦略は同じ重みで選択されることになり、完全に非合理的なプレイヤーに対する均衡を与える。
よりLQREの構造を理解するために簡単な具体例を考える。1 streetのゲームで(相手の戦略を適当に固定した場合に)、あるハンドでbetするEVが$\mathrm{EV}_{\mathrm{b}} = 2$、checkするEVが$\mathrm{EV}_{\mathrm{x}} = 1$だとする。合理性パラメータを$\lambda=1$に選んだ場合には、式(1)に従って、
$$ \begin{align*} \text{Bet頻度} &= \frac{e^{1\cdot \mathrm{EV}_{\mathrm{b}}}}{e^{1\cdot \mathrm{EV}_{\mathrm{b}}} + e^{1\cdot \mathrm{EV}_{\mathrm{x}}}} \\ \text{Check頻度} &= \frac{e^{1\cdot \mathrm{EV}_{\mathrm{x}}}}{e^{1\cdot \mathrm{EV}_{\mathrm{b}}} + e^{1\cdot \mathrm{EV}_{\mathrm{x}}}} \end{align*} $$
と書ける。すると、bet頻度はcheck頻度よりも$e^{1\cdot(\mathrm{EV}_{\mathrm{b}}-\mathrm{EV}_{\mathrm{x}})}=e\simeq 2.7$倍だけ高くなることがわかる。今度はより合理的なプレイヤーを仮定して$\lambda=10$に設定すると、betはcheckよりも$e^{10\cdot(\mathrm{EV}_{\mathrm{b}}-\mathrm{EV}_{\mathrm{x}})}=e^{10}\simeq 2.2\times 10^4$倍も高頻度で選択されることになる。BetとcheckのEVは1離れているから、$1/\lambda=0.1$よりも十分大きく、ほとんどcheckの選択肢は取られなくなったということである。
一般的に、LQREの解は次のような手続きで得られる。まず、各プレイヤーの全アクションの確率を適当に仮定して戦略を固定し、式(1)に従ってそれら戦略組に対するアクションの確率を決定する。次に、この確率が最初に仮定した確率に一致するように取る。このように自己無撞着(self-consistent)に得た全アクションの確率分布がLQREの解を与える。アルゴリズム的にこれを求める場合の手続きは、
各プレイヤーの全アクションの確率を仮定(例えばこのnodeのbet頻度50%/check頻度50%、このnodeのcall頻度30%/fold頻度70%)
→ この仮定に基づいて式(1)の右辺を計算すると各プレイヤーの全アクションの確率が新たに得られる
→ この新しい確率分布と式(1)を用いて再び新しい確率分布を得る
→ この手続きを確率分布が収束するまで繰り返す
→ 収束した先がLQREの解となる
以上をまとめると、
QREは確率的にミスをするプレイヤー同士の均衡を記述する。
QREのmodelの代表であるLQREは、低EVアクションを選択する確率が指数的に振る舞うように構成される。
LQREでは、合理性パラメータ$\lambda$によってどの程度の低EVアクションまで加味されるかが制御される。
AKQ gameのLQRE
この章では、前章で導入したLQREが実際にどのような均衡を与えるか見るために、よく知られたAKQ gameを取り上げる。
ゲーム設定
次のようにAKQ gameを設定する。
・プレイヤー1:AまたはQを等確率で持つ。
・プレイヤー2:Kを持つ。
・Pot size:1
・プレイヤー1のみが1度だけbet(またはcheck)を行うことができるとし(semi-street)、potに対するbet sizeを$B(>0)$に固定する。
・プレイヤー2はプレイヤー1のbetに対してcallまたはfoldを選択し、raiseは禁止する。
・プレイヤー1のcheckまたはプレイヤー2のcallが生じた時点でshowdownを行い、カードのランクの大きいプレイヤーがその時点のpotを獲得する。
AKQ gameのNash均衡
LQREを見る前に、AKQ gameのNash均衡をおさらいする。Nash均衡は次のようになる。
・プレイヤー1は、Aを必ずbetし、Qを確率$\frac{B}{1+B}$でbet、確率$\frac{1}{1+B}$でcheckする。
・プレイヤー2は、プレイヤー1のbetに対して確率$\frac{1}{1+B}$でcall、確率$\frac{B}{1+B}$でfoldする。
プレイヤー1のQのbet頻度(bluff頻度)は、プレイヤー2のKに対してcall or foldをindifferentにする条件から従う。プレイヤー2のKのcall頻度はプレイヤー1のQに対してbet or checkをindifferentにする条件から従う。
AKQ gameのLQREと解の意味
LQREではあらゆるアクションが式(1)の確率分布に従って決定される。Semi-streetのAKQ gameでは、ハンドごとに1度までアクションを選ぶタイミングがあり、
・プレイヤー1がAをbetする頻度を$p_{\mathrm{A}}$
・プレイヤー1がQをbetする頻度を$p_{\mathrm{Q}}$
・プレイヤー2がプレイヤー1のbetに対してKをcallする頻度を$p_{\mathrm{K}}$
と置く。
この確率分布(混合戦略)のもとでプレイヤー1がAをbetした場合にプレイヤー1が得るEVは、$\mathrm{EV}_{\mathrm{A;\mathrm{b}}} = p_{\mathrm{K}}\cdot (1+B) + (1-p_{\mathrm{K}})\cdot 1 = 1+Bp_{\mathrm{K}}$ である。一方、Aをcheckした場合にプレイヤー1が得るEVは、$\mathrm{EV}_{\mathrm{A;\mathrm{x}}} = 1$ である。すると、プレイヤー1がAをbetする確率は式(1)を用いて、$\frac{e^{\lambda\cdot\mathrm{EV}_{\mathrm{A;\mathrm{b}}}}}{e^{\lambda\cdot \mathrm{EV}_{\mathrm{A;\mathrm{b}}}} + e^{\lambda\cdot \mathrm{EV}_{\mathrm{A;\mathrm{x}}}}} = \left(1 + e^{-\lambda Bp_{\mathrm{K}}}\right)^{-1}$ となる。Aのbetする確率を$p_{\mathrm{A}}$と置いていたから、
$$ \begin{align*} p_{\mathrm{A}} = \left(1 + e^{-\lambda Bp_{\mathrm{K}}}\right)^{-1} \quad\quad (2) \end{align*} $$
が成り立つ。他のアクションについても同様の手続きで式(1)を適用できて、
$$ \begin{align*} p_{\mathrm{Q}} &= \left(1 + e^{-\lambda (1-(1+B)p_{\mathrm{K}})}\right)^{-1} \quad\quad (3) \\ p_{\mathrm{K}} &= \left(1 + e^{-\lambda \frac{-Bp_{\mathrm{A}}+(1+B)p_{\mathrm{Q}}}{p_{\mathrm{A}}+p_{\mathrm{Q}}}}\right)^{-1} \quad\quad (4) \end{align*} $$
が成り立ち、式(2)-(4)の3つの連立方程式を解けば全てのアクションの確率分布が自己無撞着に得られる。一般にこのような非線型の連立方程式は解析的に解くことが困難で、通常は数値的に解を求める。今回もBroyden法(準Newton法の一種)を用いた数値計算を行った。図1は、いくつかのbet size $B =1/3, 1/2, 1, 2, 3$に関して数値的に解いたLQREの解$p_{\mathrm{A}}, p_{\mathrm{Q}}, p_{\mathrm{K}}$を$\lambda$の関数としてプロットしたものである。なお、図中の点線はNash均衡における値を示している。
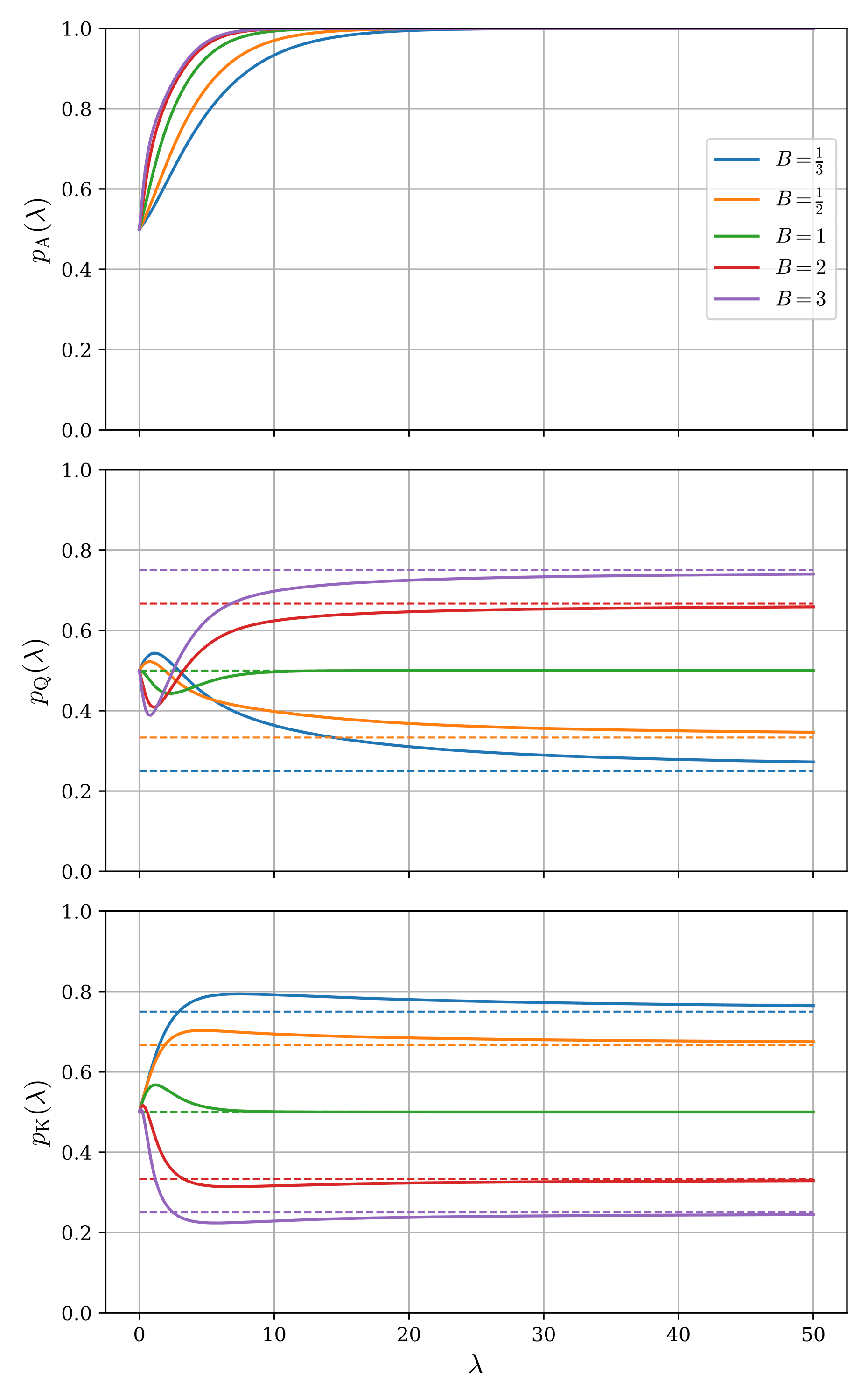
すぐにわかる事実として、$\lambda\to 0$の極限では全てのアクション頻度が1/2となっており、完全に非合理的な(つまり完全にランダムにアクションを選択する)プレイヤーを再現している。一方、$\lambda\to\infty$の極限ではNash均衡を再現することが確認できる。つまり、プレイヤー1のAのbet頻度は1に、Qのbet頻度は$\frac{B}{1+B}$に、プレイヤー2のKのcall頻度は$\frac{1}{1+B}$に近づいている。中間の領域では$\lambda$に依存して非単調な振る舞いを示している。この特徴を理解するために、両極限から少しだけ離れた場合に解がどのように振る舞うか(極限値にどのように漸近するか)を以下で確認する。
① $\lambda$が十分小さい場合(完全非合理的極限)
式(2)-(4)を$\lambda\sim 0$の下で$\lambda$の1次まで展開すると、
$$ \begin{align*} p_{\mathrm{A}} &\simeq \frac{1}{2}\left(1+\frac{Bp_{\mathrm{K}}}{2}\lambda\right) \\ p_{\mathrm{Q}} &\simeq \frac{1}{2}\left(1+\frac{1-(1+B)p_{\mathrm{K}}}{2}\lambda\right) \\ p_{\mathrm{K}} &\simeq \frac{1}{2}\left(1+\frac{-Bp_{\mathrm{A}}+(1+B)p_{\mathrm{Q}}}{2(p_{\mathrm{A}}+p_{\mathrm{Q}})}\lambda\right) \end{align*} $$
となるから、これを解けば、
$$ \begin{align*} p_{\mathrm{A}} &\simeq \frac{1}{2}\left(1+\frac{B}{4}\lambda\right) \\ p_{\mathrm{Q}} &\simeq \frac{1}{2}\left(1+\frac{1-B}{4}\lambda\right) \\ p_{\mathrm{K}} &\simeq \frac{1}{2}\left(1+\frac{1}{4}\lambda\right) \end{align*} $$
を得る。実際に図1でも$p_{\mathrm{A}}$と$p_{\mathrm{K}}$は$\lambda\sim 0$付近で正の傾きで立ち上がり、$p_{\mathrm{Q}}$はbet sizeが1より小さい場合に正の傾き、大きい場合に負の傾きで立ち上がっていることがわかる。この結果は次のように解釈できる。完全に非合理的だったプレイヤー1はわずかに合理性を獲得したために、今までの自分がどうやら強いAを打たなすぎていたのだということに気付いたのである。さらに、MDFを考えてみるとbet sizeが1より大きい時には相手がovercallになっていて、bet sizeが1より小さい時にはoverfoldになっていることに気付き、それに応じて、bet sizeが1より大きい時にはbluffを少なくして、bet sizeが1より小さい時にはbluffを多くするという決断をしたのだ。一方のプレイヤー2もやはりちょっとした合理性を獲得し、相手のbetのvalue/bluff比が1:1になっているためにbet sizeに依らずbluff過多になっていることに気付いたため、call頻度を上げることを決断した。
② $\lambda$が十分大きい場合(完全合理的極限)
式(2)-(4)を$\lambda$が十分大きいという仮定の下で展開する。各アクション確率$p_{\mathrm{X}}\,(\mathrm{X}=\mathrm{A}, \mathrm{K}, \mathrm{Q})$についてNash均衡の値を$^*$を付けて表し、$p_{\mathrm{X}} &= p_{\mathrm{X}}^* + \delta p_{\mathrm{X}}$ と書いておく。ここで、$\delta p_{\mathrm{X}}$は$\omicron(1)$である($\omicron$はLandauの記号で、$f(\lambda)$が$\omicron(g(\lambda))$であるとは$\lambda\to\infty$の極限で$\frac{f(\lambda)}{g(\lambda)}\to 0$になるという意味である)。
式(2)と$p_{\mathrm{A}}^*=1, p_{\mathrm{K}}^*=\frac{1}{1+B}$から、$\delta p_{\mathrm{A}} = -\frac{e^{-(\lambda\frac{B}{1+B}+\lambda B \delta p_{\mathrm{K}})}}{1+e^{-(\lambda\frac{B}{1+B}+\lambda B \delta p_{\mathrm{K}})}} = -e^{-(\lambda\frac{B}{1+B}+\lambda B \delta p_{\mathrm{K}})} + \omicron(e^{-\lambda\frac{B}{1+B}})$ が成り立つ。式(3)と$p_{\mathrm{Q}}^*=\frac{B}{1+B}, p_{\mathrm{K}}^*=\frac{1}{1+B}$から、$\delta p_{\mathrm{Q}} = \frac{1}{1+e^{\lambda(1+B)\delta p_{\mathrm{K}}}} - \frac{B}{1+B}$ で、右辺が$\omicron(1)$となるためには$e^{\lambda(1+B)\delta p_{\mathrm{K}}}\to 1/B$となればよく、$\delta p_{\mathrm{K}} = -\frac{\ln B}{1+B}\frac{1}{\lambda} + \omicron(\lambda ^{-1})$ が導ける。最後に式(4)より、$\delta p_{\mathrm{K}} = \frac{1}{1+e^{-\lambda\frac{-Bp_{\mathrm{A}}+(1+B)p_{\mathrm{Q}}}{p_{\mathrm{A}}+p_{\mathrm{Q}}}}} - \frac{1}{1+B}$ の右辺が$\omicron(1)$となることから、
$$ \begin{align*} \frac{-Bp_{\mathrm{A}}+(1+B)p_{\mathrm{Q}}}{p_{\mathrm{A}}+p_{\mathrm{Q}}} &= \frac{-B\delta p_{\mathrm{A}}+(1+B)\delta p_{\mathrm{Q}}}{p_{\mathrm{A}}^*+p_{\mathrm{Q}}^*} + \omicron(\lambda^{-1}) \\ &= \frac{1+B}{1+2B}(-B\delta p_{\mathrm{A}}+(1+B)\delta p_{\mathrm{Q}}) + \omicron(\lambda^{-1}) \end{align*} $$
に注意すると、$\delta p_{\mathrm{Q}} = -\frac{1+2B}{(1+B)^2}\ln B\cdot\frac{1}{\lambda} + \omicron(\lambda^{-1})$ が得られる。最終的な結果をまとめると、
$$ \begin{align*} p_{\mathrm{A}} &= 1 - \left(\frac{1}{B}\right)^{\frac{B}{1+B}}e^{-\frac{B}{1+B}\lambda} + \omicron(e^{-\frac{B}{1+B}\lambda}) \quad\quad (5) \\ p_{\mathrm{Q}} &= \frac{B}{1+B} - \frac{1+2B}{(1+B)^2}\ln B\cdot\frac{1}{\lambda} + \omicron(\lambda^{-1}) \quad\quad (6) \\ p_{\mathrm{K}} &= \frac{1}{1+B} - \frac{\ln B}{1+B}\frac{1}{\lambda} + \omicron(\lambda^{-1}) \quad\quad (7) \end{align*} $$
となる。注目すべき点として、$p_{\mathrm{A}}$は$\lambda$に関して指数的に極限値に漸近するということである。$p_{\mathrm{Q}}$や$p_{\mathrm{K}}$は$\lambda^{-1}$の冪でゆっくり極限値に近づく一方で、$p_{\mathrm{A}}$はプレイヤーの合理性とともに急速に収束する。また、指数の$\frac{B}{1+B}$は$B$に関して単調増加であるから、bet sizeが大きくなるほどより急速に漸近することもわかる。図1を見てみると、確かに$p_{\mathrm{A}}$は他に比べて急速に極限値に張り付いていて、そのbet size依存性も確認できる。Nash均衡ではAにcheck頻度はないために、合理性によって強く"禁止"されていると言える。Nash均衡においてあるアクションのEVがそれ以外のアクションのEVよりも高いという事実が、単にLQREでそれぞれのアクションを選択する確率に反映されるというだけでなく、合理性に対する振る舞いに質的違いをもたらすという点で非常に興味深い。
細かい点だが、$B=1$の場合について補足する。式(6)と(7)からわかる通り、$B=1$では$p_{\mathrm{Q}}$と$p_{\mathrm{K}}$の$\lambda^{-1}$の係数が0になってしまう。記事内では詳しい計算は割愛するが、$B=1$の場合には実は$p_{\mathrm{Q}}$と$p_{\mathrm{K}}$の$\lambda\to\infty$の漸近形はもはや冪関数ではなく指数関数となる。図1からも読み取れる通り、非常に急速に極限値の$1/2$に近づいている。このような指数的な振る舞いはある意味臨界的(critical)と呼べるような現象で、特殊な値について発生している"異常な"事態である。
次に、$p_{\mathrm{Q}}$と$p_{\mathrm{K}}$の$\lambda^{-1}$の係数に注目すると、bet sizeが1より大きい時/小さい時でそれぞれ下から/上から極限値に近づくことがわかる。実際に図1からもこのことは読み取れる。この事実は次のように解釈することができる。完全合理的だった2人のプレイヤーは、お互いにわずかに合理性を失ったためにミスをするようになる。プレイヤー1は、bluff bet(Qのbet)をする際にbet sizeが大きい時にはリスクを感じてbluff頻度が減り、bet sizeが小さい時にはリスクが軽減されたように感じてbluff頻度が増える。それに応じてプレイヤー2は、bet sizeが大きい時にはcall EVがfold EVよりも低く感じていて、bet sizeが小さい時にはcall EVがfold EVよりも高く感じている(その結果としてNash均衡では$B=1$を境にcall頻度とfold頻度が逆転する)。逆に、プレイヤー2がKでcallをする際には、bet sizeが大きい時にはやはりリスクを感じてcall頻度が減り、bet sizeが小さい時にはリスクが軽減されてcall頻度が増える。それに応じてプレイヤー1は、bet sizeが大きい時にはQのbluff bet EVがcheck EVよりも高く、bet sizeが小さい時にはbluff bet EVがcheck EVよりも低く感じている(その結果としてNash均衡では$B=1$を境にQのbluff bet頻度とcheck頻度が逆転する)。
LQREのexploitability
本章では、LQREの精度を確かめることにする。戦略がどの程度exploitされ得るかを示す指標としてexploitability (=Nash distance)が知られている。Exploitabilityは、ある戦略がその戦略に対するmaximally exploitative strategy (MES)と相対した場合に、GTO戦略が保証するEVに比べてどの程度EVを損するかという量である。
以下ではプレイヤー1のexploitability $\varepsilon$を見積もる。LQREにおけるプレイヤー1の戦略のvalue/bluff比がNash均衡のそれよりもvalueに寄っている(=value-heavy)場合にはプレイヤー2はKを必ずfoldすることがMESとなる。逆にプレイヤー1のbetのvalue/bluff比がbluffに寄っている(=bluff-heavy)場合にはプレイヤー2はKを必ずcallすることがMESとなる。このことに注意すると、
・Bluff-heavyの場合、プレイヤー1の戦略のEVは$\frac{1}{2} + \frac{B}{2}(p_{\mathrm{A}} - p_{\mathrm{Q}})$
・Value-heavyの場合、プレイヤー1の戦略のEVは$\frac{1}{2}(1+p_{\mathrm{Q}})$
と計算できる。GTO戦略におけるプレイヤー1の得るEVは$\frac{1+2B}{2(1+B)}$であるから、そこから上記のMESに相対した場合に得るEVを差し引けば、
$$ \begin{align*} \varepsilon = \begin{cases} \frac{B}{2(1+B)} - \frac{B}{2}(p_{\mathrm{A}} + p_{\mathrm{Q}}) & \text{if bluff-heavy} \\ \frac{B}{2(1+B)} - \frac{p_{\mathrm{Q}}}{2} &\text{if value-heavy} \end{cases} \quad\quad (8) \end{align*} $$
数値的に得られたLQREの結果を用いてexploitabilityを$\lambda$の関数としてプロットしたものが図2である。$\lambda$が増加するとLQREはNash均衡に近づきexploitabilityは0に収束していることがわかる。
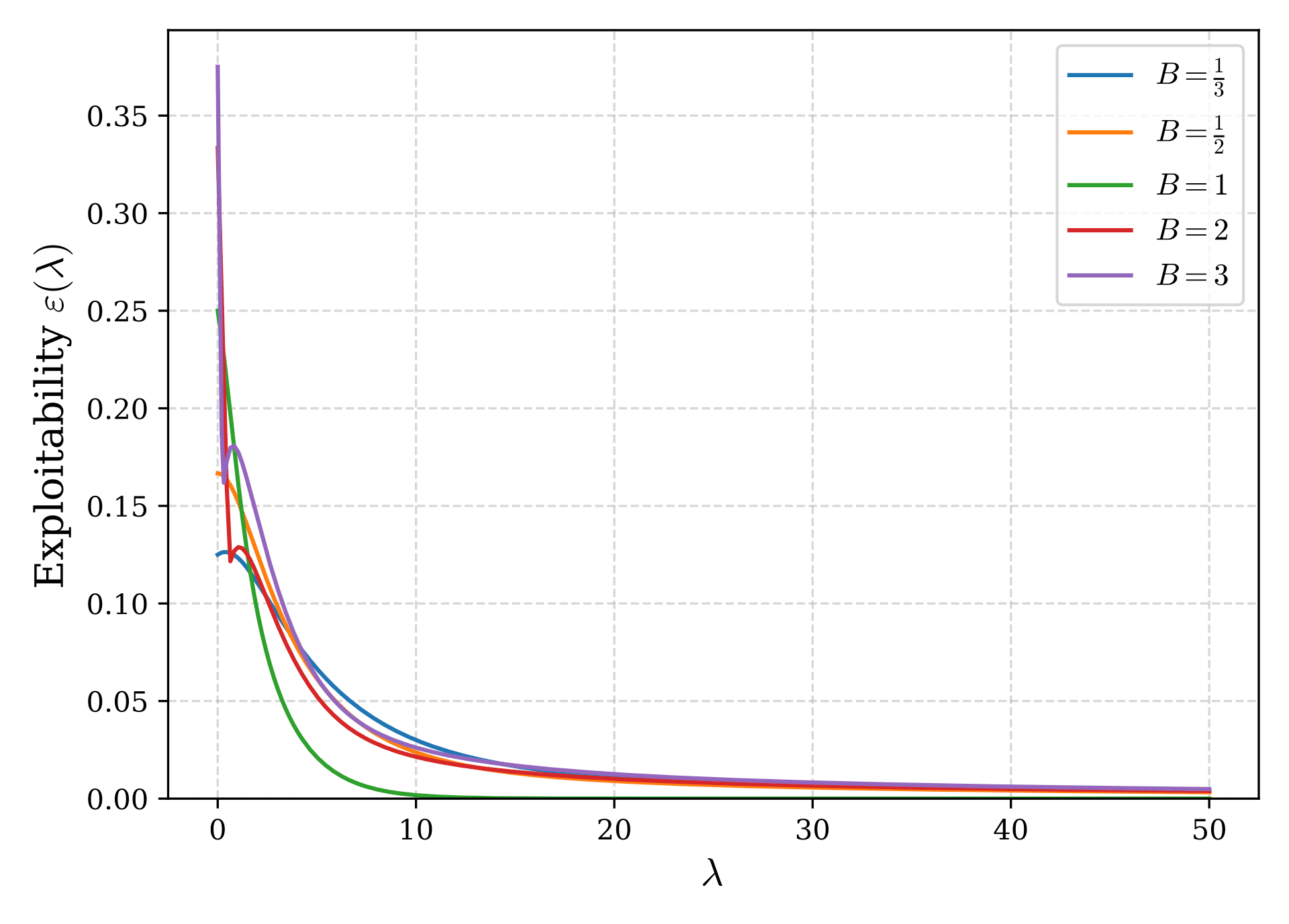
どの程度の$\lambda$を選択すればexploitabilityが十分小さくなるかを調べるために、先に導いた$\lambda\to\infty$の漸近解を用いて$\varepsilon$を評価する。式(8)に式(5)と(6)を代入することで、$\lambda\to\infty$で、
$$ \begin{align*} \varepsilon(\lambda) &=\begin{cases} -\frac{\delta p_{\mathrm{Q}}}{2}& \text{if } B >1 \\ -\frac{B}{2}(\delta p_{\mathrm{A}} - \delta p_{\mathrm{Q}}) & \text{if } B <1 \end{cases} \\ &= \begin{cases} \frac{1+2B}{2(1+B)^2}\ln B\cdot\frac{1}{\lambda} + \omicron(\lambda^{-1})& \text{if } B >1 \\ -\frac{B(1+2B)}{2(1+B)^2}\ln B\cdot\frac{1}{\lambda} + \omicron(\lambda^{-1}) & \text{if } B <1 \end{cases} \end{align*} $$
を得る。ここで、場合分けは$\lambda$が十分大きい場合には$B\gtrless 1$でそれぞれvalue-heavyとbluff-heavyになることによる(先の議論を参照)。重要な点として、exploitabilityのleading orderは$\Omicron(\lambda^{-1})$となることである($\Omicron$はLandauの記号で、$f(\lambda)$が$\Omicron(g(\lambda))$であるとは$\lambda\to\infty$の極限で$\frac{f(\lambda)}{g(\lambda)}\to \mathrm{const.}$となることを表す)。これは$p_{\mathrm{Q}}$の漸近形に由来している。$p_{\mathrm{A}}$は指数的に漸近するものの、exploitabilityは全てのハンドを考慮するため最も収束の遅い$p_{\mathrm{Q}}$の$\Omicron(\lambda^{-1})$の項を拾ってくるというわけである。
例えば、$B=2$や$B=1/2$の場合には、$1/\lambda$の係数はそれぞれ$\frac{5\ln2}{18}\simeq 0.1925$と$\frac{2\ln2}{9}\simeq 0.1540$となるから、いずれの場合にも$\lambda = 2000$などと取ればexploitabilityはpotの0.1%未満に収まることが期待される。なお、0.1%という値はGTO Wizard blogにて
GTO Wizard AIはポットサイズのおよそ0.1%までしか搾取できないようなナッシュディスタンスまで解を収束させています。
と言及されている。$\lambda = 2000$の場合には、式(5)-(7)から分かる通り$p_{\mathrm{A}}$は限りなく1に近く、$p_{\mathrm{Q}}$と$p_{\mathrm{K}}$のは0.1%程度Nash均衡における値からずれる。99.9%の精度で近似的にNash均衡であると言っても良い($\varepsilon$-均衡とも呼ばれる)。つまり、今回GTO Wizardに導入されたQREは、これまで我々が見てきたNash均衡に基づくGTO戦略とほとんど変わらないのである。
[補足:これまでのGTO Wizardで遷移確率がないために計算が収束していなかったnode(いわゆるゴーストライン)が改善されているという意味での変化はあるが、やはり遷移確率自体は実際上においては無視できるほど低いので、QREはこれまでのNash均衡に基づくGTO戦略とほとんど一緒と言っても差し支えない。しかし、複数のNash均衡が存在する場合にCFRによって求めた$\varepsilon$-均衡とQREによる$\varepsilon$-均衡とが異なる(戦略的に離れている)場合はありうる]
まとめ
QREは確率的にミスをするプレイヤー同士の均衡を記述し、その代表的なmodelにLQREがある。LQREでは合理性パラメータ$\lambda$によってどの程度の低EVアクションまで加味されるかが制御される。
本稿では、AKQ gameに対してLQREを数値的に求めた。$\lambda\to 0$と$\lambda\to\infty$の2つの極限と漸近の仕方は解析的に調べることができる。
特に、$\lambda\to\infty$ではLQREはNash均衡に近づき、Nash均衡で純粋戦略を採るべきAは指数的に急速に漸近する一方で、混合戦略を採るそれ以外のハンドは冪的にゆっくり漸近することを示した。
LQREのexploitabilityは、A以外のハンドの冪的な漸近に律速を受けて$1/\lambda$に比例して0に収束していく。
AKQ gameの場合には$\lambda=2000$程度に取ればexploitabilityをpotの0.1%未満に抑えることができるということを具体的に確認した。この時各アクションの確率分布はNash均衡の場合と0.1%程度しか変わらない。
補足:統計力学的アナロジー
統計力学との対応関係
LQREは物理学における統計力学と密接な関係がある。LQREの根幹を成す式(1)の確率分布は統計力学ではBoltzmann分布と呼ばれる。Boltzmann分布は、古典的粒子集団(量子力学ではなく古典力学に従う粒子の集団)のエネルギー分布を記述し、その粒子の集団が状態$i$にある確率はその状態のエネルギーを$\epsilon_i$として、
$$ \begin{align*} \frac{e^{-\beta\epsilon_i}}{\sum_j e^{-\beta\epsilon_j}} \quad\quad (9) \end{align*} $$
で与えられるとする。ここで、$\beta$は温度の逆数を表し、逆温度(inverse temperature)と呼ばれる。式(1)と式(9)を見比べると、次のような対応関係があることがわかる:
$$ \begin{align*} \epsilon_i &= - \mathrm{EV}(a_i,P_{-i}) \quad\quad (10) \\ \beta &= \lambda \quad\quad (11) \end{align*} $$
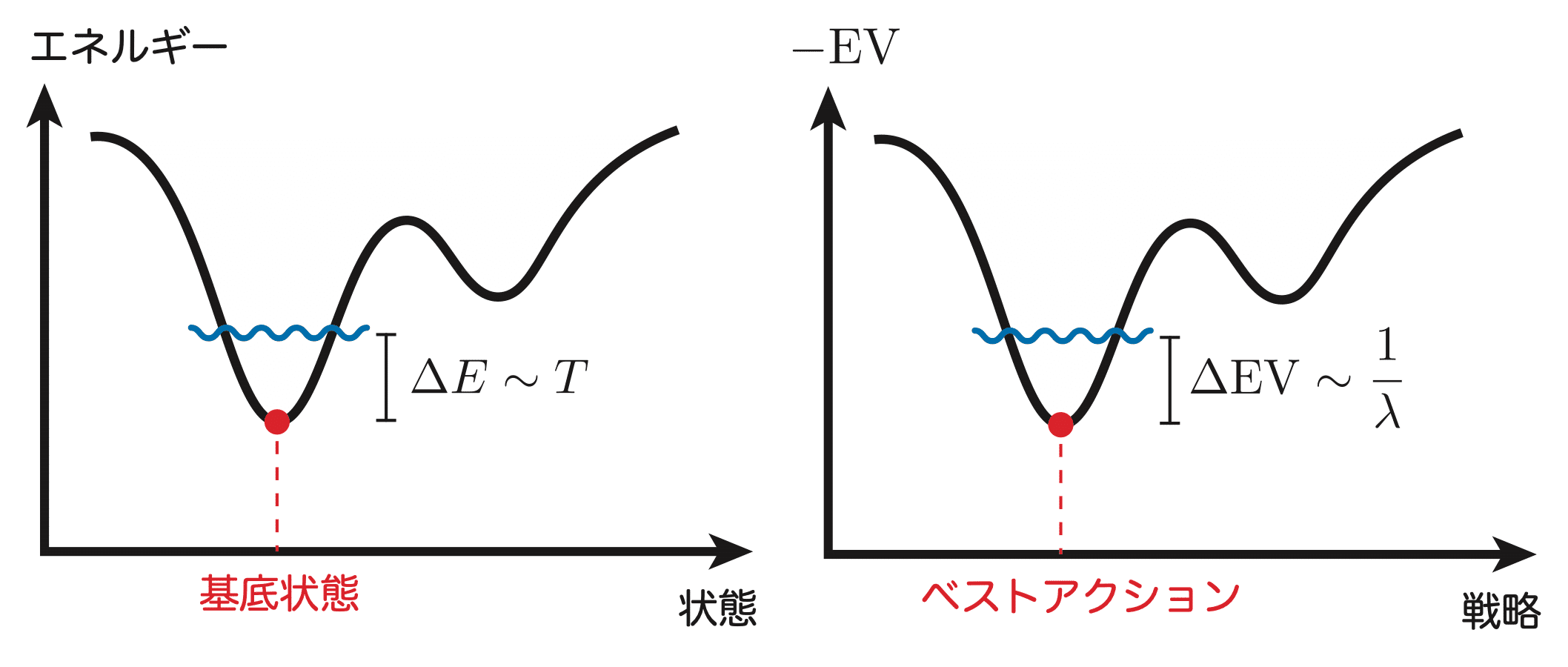
式(10)の負号は、ポーカー(やゲーム理論)における期待利得は最大値を取ることが選択される一方で、物理においてはエネルギーの低い状態が選択されることに由来する。式(11)は、$1/\lambda$が温度$T$に対応することを表す。物理においては、絶対零度($T=0$)では最低エネルギーの状態(基底状態と呼ばれる)のみが実現し、これは$\lambda\to\infty$の完全合理的極限における最大EVアクションのみが実現するNash均衡に対応する。有限温度では、粒子の集団は最低エネルギー状態のみを取るわけではなく、温度$T$に対応するエネルギー程度の励起(=高エネルギー状態への遷移)を許す。高温極限($T\to\infty$)では粒子の集団があらゆる状態を取り、LQREにおける$\lambda\to 0$の完全非合理性極限に対応することもわかる。
図3には統計力学(左)とLQRE(右)の対応のイメージを描いている。有限温度では基底状態からの温度ゆらぎで高いエネルギーの状態へ励起できることに対応して、LQREではベストアクション(=最高EVのアクション)よりも合理性パラメータの逆数程度低いEVを持つアクションが加味される。
この対応関係を考慮すると、ポーカー(より一般にはゲーム理論)におけるLQREは温度$1/\lambda$における熱平衡状態にある戦略分布を記述していると言える。すると、ポーカーに対して種々の状態量や熱力学関数が定義できる。例えば、プレイヤー$i$の混合戦略$P_i$に対してエントロピー$S(P_i,P_{-i})$が $S(P_i,P_{-i}) = - \sum_{a_i} P_i(a_i)\ln P_i(a_i)$ と定義できる。ただし、$P_i(a_i)$は式(1)で定められるLQREの確率分布である。エントロピーは物理では系の乱雑さの指標になる。ポーカー(またはゲーム理論)では混合戦略のランダムさを表す。混合戦略がどの程度"不確定か"、どの程度の"情報量"を持つかを示す指標と言うこともできる。エントロピーを用いると新たに(Helmholtzの)自由エネルギー$F(P_i,P_{-i})$を定義することができる:
$$ \begin{align*} F(P_i,P_{-i}) = E(P_i,P_{-i}) - \frac{1}{\lambda}S(P_i,P_{-i}) \quad\quad (12) \end{align*} $$
ここで、
$$ \begin{align*} {E(P_i,P_{-i})=-\sum_{a_i}P_i(a_i)\cdot\mathrm{EV}(a_i,P_{-i})} \quad\quad (13) \end{align*} $$
は内部エネルギーと呼ばれ、あるnodeにおけるEVを表す。物理における自由エネルギーは、簡単に言うと仕事として取り出せるエネルギーのことで、系の安定性を与える関数である。系は自然に自由エネルギーを最小化するように動き、熱平衡状態に到達する。つまり、熱平衡状態では自由エネルギーは最小値を取る。
実は、自由エネルギーに対する変分問題としてLQREを定式化することもできる。以下では、式(1)の確率分布の具体形を所与のものとせず、熱平衡状態で式(12)の自由エネルギーが最小化されるべきという条件から逆に式(1)を導く。このためには、確率分布に対する拘束条件$\sum_{a_i} P_i(a_i) = 1$ を考慮し、Lagrangeの未定乗数$\mu$を導入して、$\mathcal{F}[P_i] = F(P_i,P_{-i}) + \mu\left(\sum_{a_i}P_i(a_i)-1\right)$ で定義した汎関数$\mathcal{F}[P_i]$の汎関数微分が0になればよく、$\frac{\delta\mathcal{F}}{\delta P_i(a_i)} = 0$ が熱平衡状態で成り立つ。式(12)と(13)の表式を用いて汎関数微分を実行すると、$-\mathrm{EV}(a_i,P_{-i}) - \frac{1}{\lambda}(1 + \ln P_i(a_i)) + \mu = 0$ となり、これを解くと、$P_i(a_i) = (\mathrm{const}.)\times e^{\lambda\cdot\mathrm{EV}(a_i,P_{-i})}$ となる。これを規格化すれば、$P_i(a_i) = \frac{e^{\lambda\cdot\mathrm{EV}(a_i,P_{-i})}}{\sum_{a_i'}e^{\lambda\cdot\mathrm{EV}(a_i',P_{-i})}}$ が導かれ、これはまさしく式(1)のLQREの確率分布である。
混合戦略の内部エネルギー、エントロピー、自由エネルギー
最後の節では、統計力学との対応の節で導入した内部エネルギー、エントロピー、自由エネルギーといった状態量及び熱力学関数についての計算結果を提示する。内部エネルギーはEVに符号を付けたもの、エントロピーは、混合戦略がどの程度各アクションを混ぜているかを示しており、自由エネルギーは混合戦略の安定性の指標となっていたのであった。
図4にはハンドごとの内部エネルギー$E_{\mathrm{X}}$、エントロピー$S_{\mathrm{X}}$、自由エネルギー$F_{\mathrm{X}}$を$\lambda$の関数としてプロットしている。ただし、${\mathrm{X}} = \mathrm{A}, \mathrm{Q}, \mathrm{K}$で、それぞれのハンドを列ごとに示している。
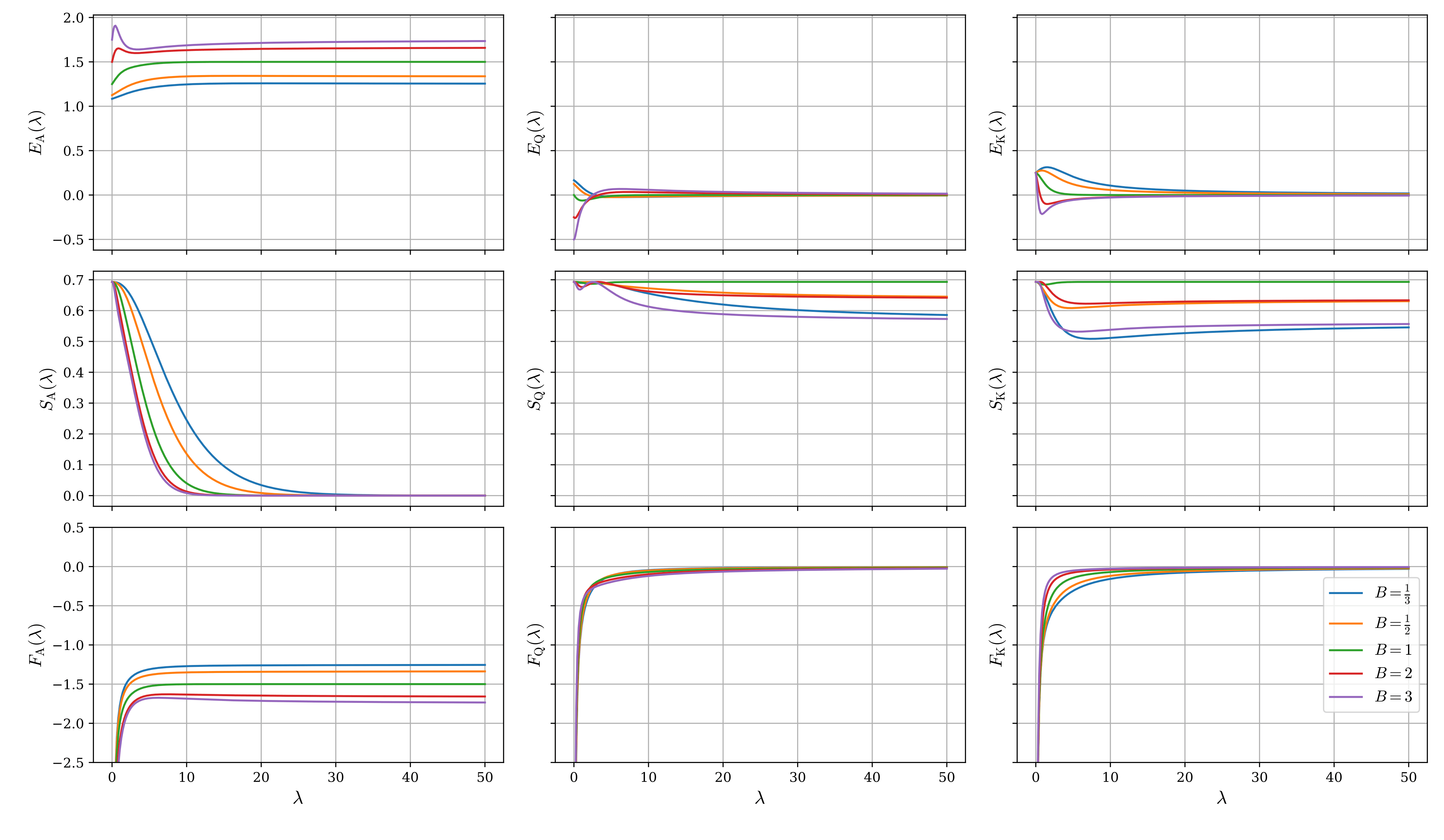
$\lambda\to 0$の極限では、全てのアクションは等確率で発生し、完全にランダムな混合戦略を成す。そのため、エントロピーは最大値の$\ln 2$を取る。プレイヤー1のAはNash均衡ではbetのみの純粋戦略を採るため、$\lambda\to\infty$の極限ではエントロピーは最低値の0に収束する。それ以外のハンドではNash均衡でも混合戦略となるために、エントロピーは有限値に落ち着いている。
自由エネルギーは$F_{\mathrm{X}} = E_{\mathrm{X}} - \frac{1}{\lambda}S_{\mathrm{X}}$であり、$\lambda$を増加させると、エントロピーの第二項がほとんど寄与しなくなって内部エネルギーに一致する。前述したように、LQREは自由エネルギーを最小化するように確率分布を与えることで得られるから、合理的なプレイヤーはEV(内部エネルギーに負号を付けたもの)を最大化するように戦略を決定するということが理解できる。逆に$\lambda$を減少させると、エントロピーの第二項が大きな寄与を示すようになるから、できるだけ混合戦略をランダムに取ってエントロピーを大きくすることが自由エネルギーを小さくさせる方向に働くということがわかる。
おわりに
この記事が参考になったら
ブックマークしていつでも見返せるようにしましょう!
Ctrl+D(Macは⌘+D)で追加できます。
この記事に誤りや不明点があれば、お気軽にご連絡ください。
✉️ 運営に連絡する


